

Enterprise WordPress projects differ substantially from a typical WordPress project, which might simply be a custom theme with some posts, pages, and a widgetized sidebar or two. Human Made’s recent partnership with Fairfax Media was no exception: there were no pages, no widgets and there certainly wasn’t a theme. The built-in media library was completely removed, the ability to modify terms was disabled, and many of WordPress’s default roles were replaced or disabled.
What did remain were posts (renamed articles in the UI) and a heavily modified edit screen. Working with Fairfax’s internal CMS development team, we essentially rebuilt the WordPress edit screen from the ground up while maintaining many of the technical features of WordPress.
Why rebuild the edit screen?
The need to improve the WordPress default editing experience is perhaps best illustrated by the current major project to do just that for WordPress straight out of the box, codenamed Gutenberg.
While a traditional WordPress project shares some requirements with those of enterprise clients, many others are quite different and require rethinking the editing experience and related workflow. This was particularly the case for Fairfax, a national publisher moving from a proprietary to open source CMS, managing three large mastheads through a single instance of WordPress.
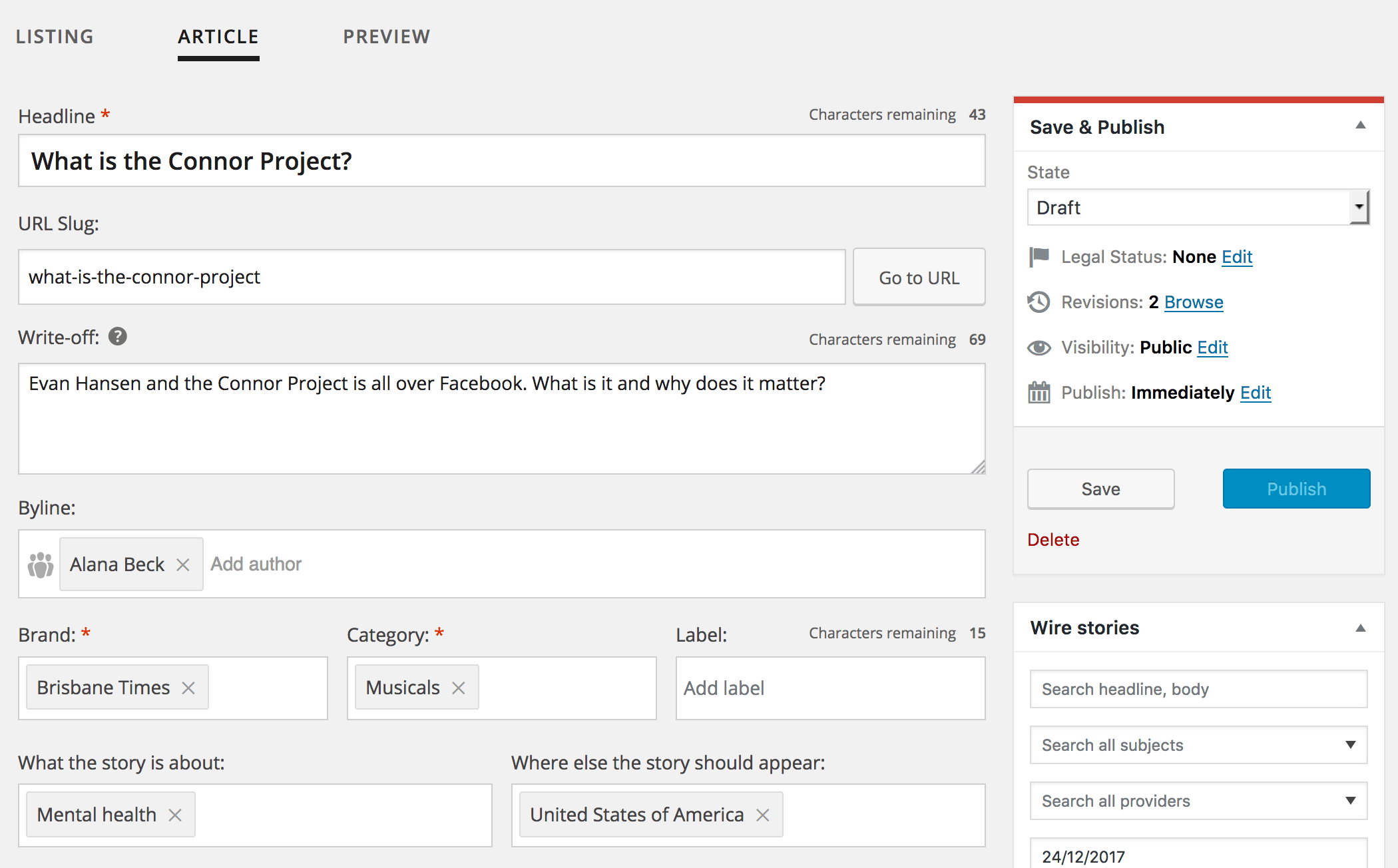
Many of the changes we made to the edit screen modified default features to improve their operation on a large scale, making them more efficient and usable at scale. Major interface changes were made to the edit screen, a tabbed interface was introduced to separate the meta data required for commissioning an article – such as deadline, the writing team, and the brief – from the fields required for authoring an article – such as the introduction, the content and specifying a byline.
Some of the default features replaced with custom-built interfaces were the publishing and taxonomy metaboxes, and the post slug interface. The author field was also expanded to allow multiple authors and to provide a way to specify collaborators and editors of the story.
Many of the custom fields were added to the screen using CMB2, our preferred library for adding data to the edit screen. CMB2 was also used to modify the interface with custom display and Ajax callbacks.
Technical details
The Fairfax CMS includes a custom hierarchical taxonomy containing around 22,000 terms. By default, WordPress will attempt to create a metabox containing a checkbox list of each of these terms:
> document.querySelectorAll( '#custom_taxochecklist li' ).length
22092The default metabox in WordPress is not designed for this scale (nor should it be, it’s an extreme edge case): aside from becoming impractical for an author to use, it adds inefficient database calls to the page load (in this case returning 80,000 rows across two queries) and adds 3.5MB to the HTML weight.
To work around this, we replaced the metabox with a custom-built select2 metabox for CMB2. This uses a custom Ajax call to query for terms, minimising the impact to the page. We further tweaked the query to allow users to search against parent terms (searching location to return all locations, company for all companies) and we paginated the results to avoid slowing down the request with large result sets.
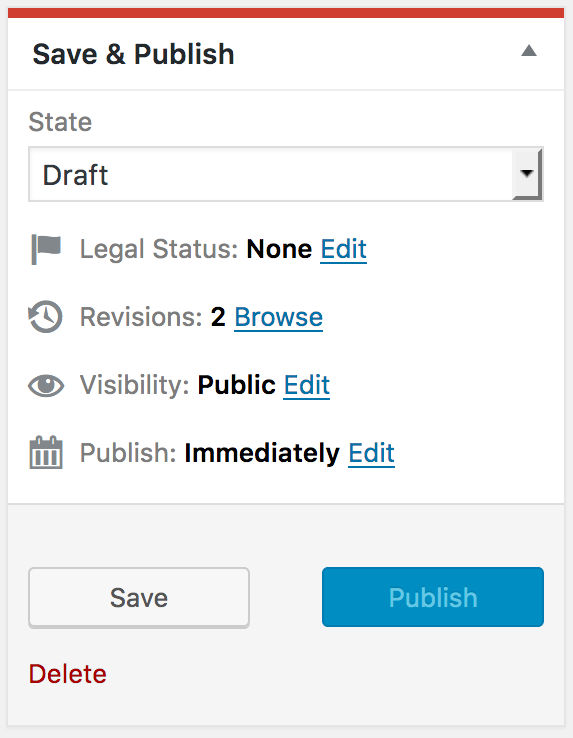
Custom publishing and workflow
Rather than modifying the existing publishing metabox in WordPress, we found it was easier to replace it than attempt to modify it via hooks and actions. This metabox was replaced with what we dubbed the Publish Box of the Future (PBotF). Despite the grandiose name, this began as a simple prototype that evolved over time into a real replacement for the existing metabox. This allowed us to develop the partially-functional prototype while keeping the legacy metabox around until it reached feature parity.
Using a custom metabox allowed us to implement custom workflow requirements, such as legal status, scheduling the time for unpublishing an article, and allowing for drafts of after-publication edits. It also allowed us to save the post and associated data via the WordPress REST API to avoid full page refreshes.
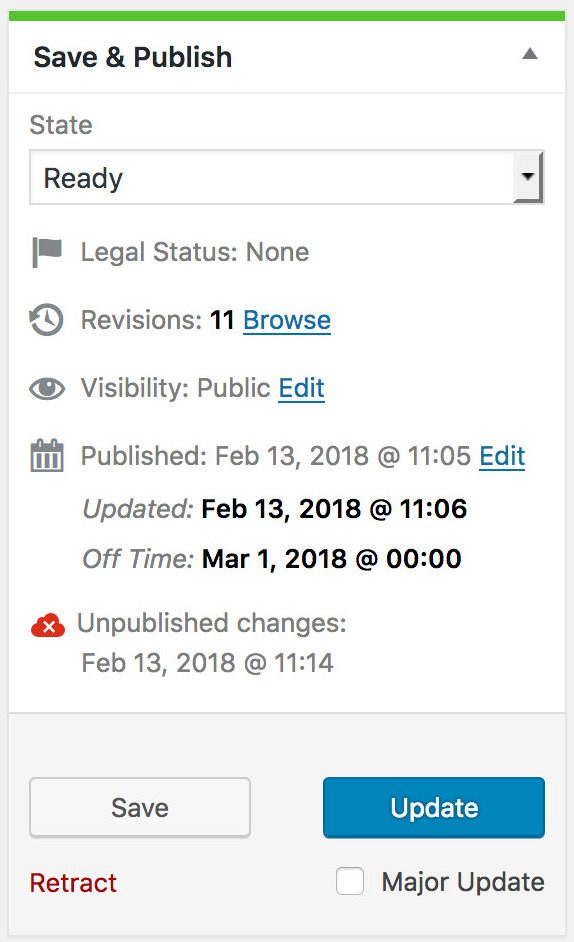
The PBotF was built using existing libraries within WordPress, including Backbone, jQuery and the REST API Backbone JavaScript client, allowing us to take advantage of the existing functionality without having to build it all from scratch.
Modelling data with the WordPress REST API
The ability to save via the REST API required adding custom fields and taxonomies to the built in post endpoint. In a CMS of the scale of Fairfax’s, these quickly add up: we needed to add 61 custom fields to the endpoint and several taxonomies. In all instances, these were prefixed with ffx_ to ensure we didn’t clash with another plugin’s data and to reduce the chance of a WordPress update introducing a field of the same name.
register_rest_field(
'post',
'ffx_custom_field',
[
'get_callback' => __NAMESPACE__ . '\\get_custom_field',
'update_callback' => __NAMESPACE__ . '\\set_custom_field',
'schema' => [
'description' => __( 'Fairfax custom field, 'ffx' ),
'type' => 'boolean',
],
]
);By registering the fields with the REST API and including a schema, we were able to take advantage of several WordPress core features. By specifying the field’s type (boolean in the example above), the REST API automatically performs validation and sanitization of the data when saving.
The REST API Backbone client uses this same schema to provide the model when saving to the endpoint, giving developers a significant head start there too (thus our decision to stick with the arguably dated libraries).
While much of the existing state PBotF was stored in the custom Backbone model, we needed to break out of the box to access many of the regular post fields on the page. Rather than rebuild the entire edit screen (a task the Gutenberg team have taken on with React), we decided to simply break out of the box using jQuery to access the fields.
const getFormData = function () {
const postData = {
title: $( '#title' ).val() || '',
content: $( '#content' ).val() || '',
excerpt: $( '#excerpt' ).val() || '',
ffx_custom_field: $( '#cmb2-id--ffx-custom-field input' ).is( ':checked' ),
ffx_custom_field_ii: $( '#_ffx_custom_field_ii' ).val() || '',
// snipped
}
};Saving with revisions
As part of adding custom properties to the edit screen, we needed revisions to include a bunch of additional content. For this we used Adam Silverstein’s post meta revisions plugin.
Once we switched to the Publish Box of the Future we started experiencing an off-by-one error when saving revisions: updates to meta were be stored against the next revision. Investigation revealed that this was due to internal behaviour in the WordPress REST API.
When saving with the standard publish box, wp_insert_post is used to update the post’s content, the taxonomies and meta. At the end of wp_insert_post a new revision is generated. However, the REST API only uses wp_insert_post to save the post content and other data stored in the post table. Taxonomy and meta are then updated separately, changing the order in which things happen. This means that by default in the REST API, revisions are created before the post data has finished updating; this becomes a problem once revisions include meta.
To solve this, on REST API requests we remove the revision callback from running at the end of wp_insert_post, and instead generate the revision at the conclusion of the REST API request:
/** Move the 'wp_save_post_revision' callback for REST requests. */
function move_revision_callback( $result, $unused, $request ) {
/* SNIP: Check for post update request */
// Move default `wp_3_save_post_revision` callback.
remove_action( 'post_updated', 'wp_save_post_revision', 10 );
add_action( 'rest_request_after_callbacks', 'wp_save_post_revision');
return $result; // Support other filters.
}
Tabbed layout of the edit screen
While replacing the publishing box allowed for technical control of the publishing process, we also needed to modify the edit screen to allow for the human side the process. Large publishers with multiple mastheads have naturally-complex processes, with many people involved in the process of publishing a single article. Using the magical power of JavaScript, we switched the edit screen to a tabbed layout, separating the editorial interface from the reporting experience.
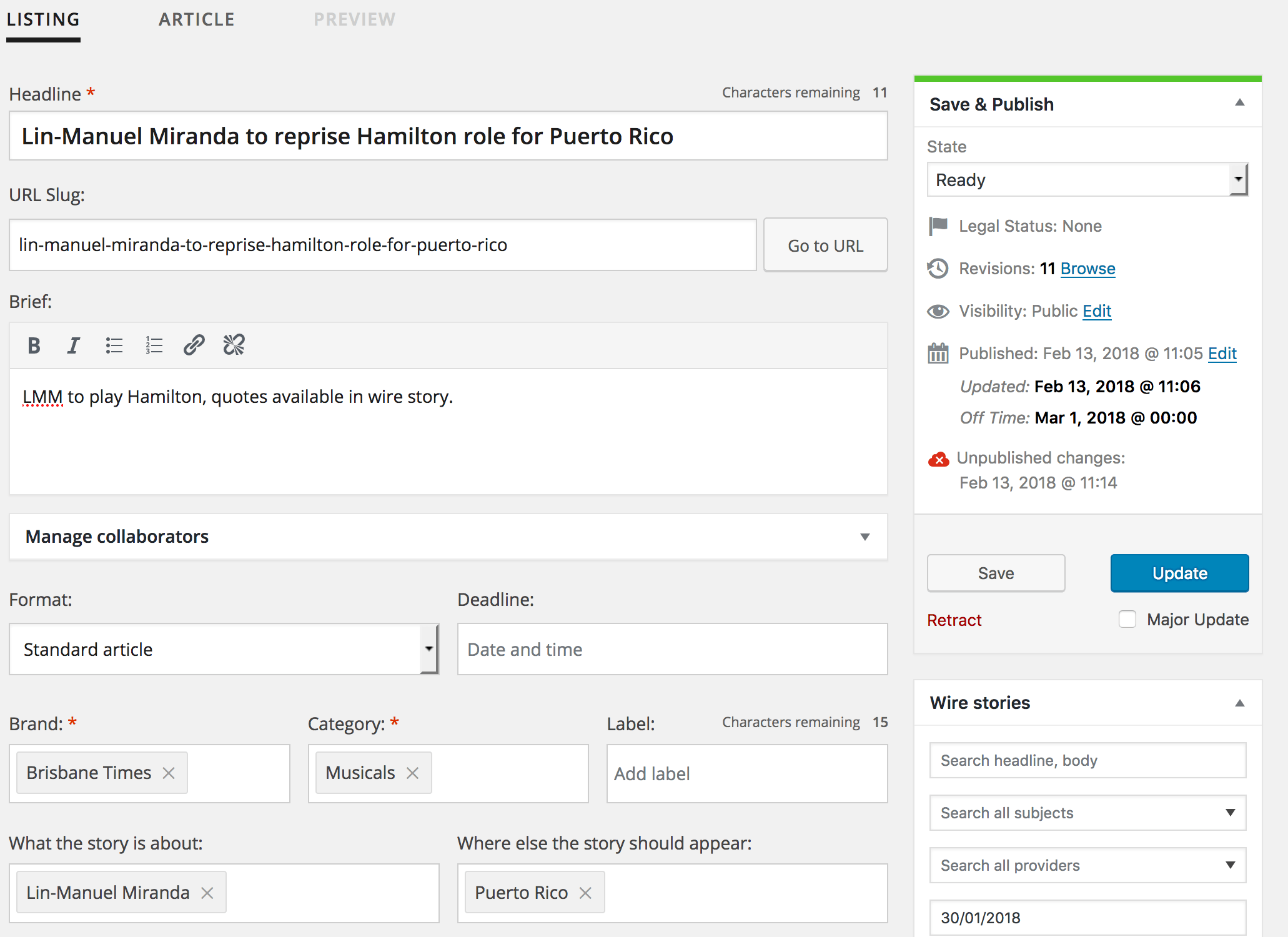
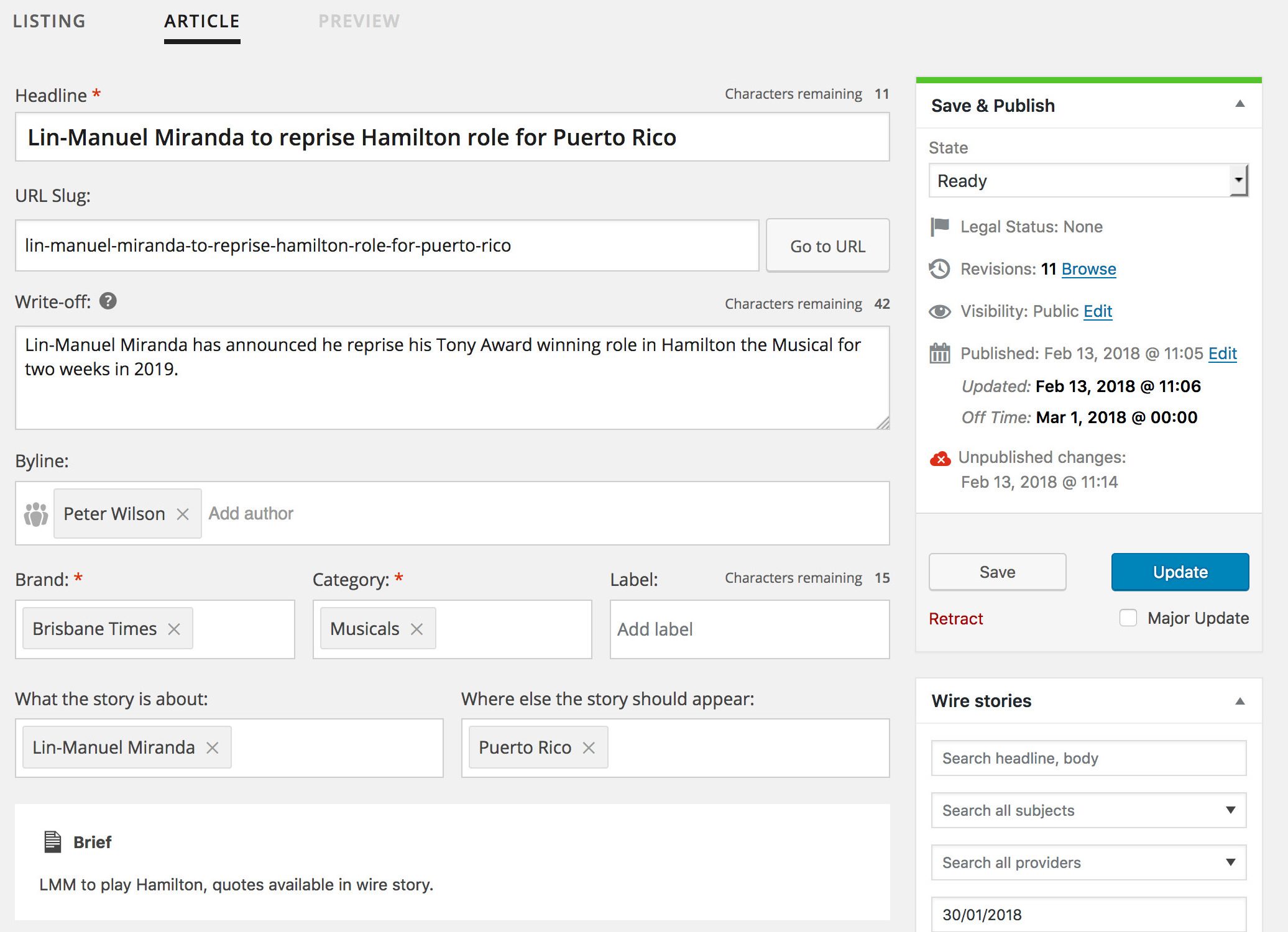
Since the post screen doesn’t natively support a tabbed layout, we had to create our own using some creative uses of the WordPress hooks API. We used the generic all_admin_notices action to add the tab markup in the notifications area, scoped to the edit screen using the load-post.php and load-post-new.php hooks. For switching between tabs, we applied a helper class to the body element indicating which tab we were on. When registering the CMB2 fields, we included helper classes indicating on which tab (or tabs) the field ought to be displayed on:
$field = [
'id' => '_ffx_custom_field',
'classes' => [
'ffx-show-on-listing',
],
];
This made managing the display a case of some simple CSS:
.ffx-show-on-listing,
.ffx-show-on-article {
display: none;
}
body.ffx-tab-listing .ffx-show-on-listing,
body.ffx-tab-article .ffx-show-on-article {
display: inherit;
}
While the tabs were one of the simpler challenges technically (barring a few race conditions in JavaScript), they ended up providing the most value for the user through the clarified interface.
Conclusion
Building a custom editing interface allowed us to take WordPress well beyond its blogging and small business stereotype, with a brand new, modern experience via the WordPress REST API. This allowed us to scale to tens of thousands of terms and hundreds of thousands of post objects while keeping a usable editorial workflow. Combined with other custom features – including enhanced media management, access to wire services, and Slack integration – we were able to produce a true enterprise product.
While the quality of the code undoubtedly contributed to creating an enterprise product, the process around writing the code was of much greater significance. Code review and a strict adherence to scrum (including all the meetings developers love to hate) allowed us to scale the process and work effectively, taking open source well beyond the stereotype, with more than 11 thousand commits and over 30 committers.
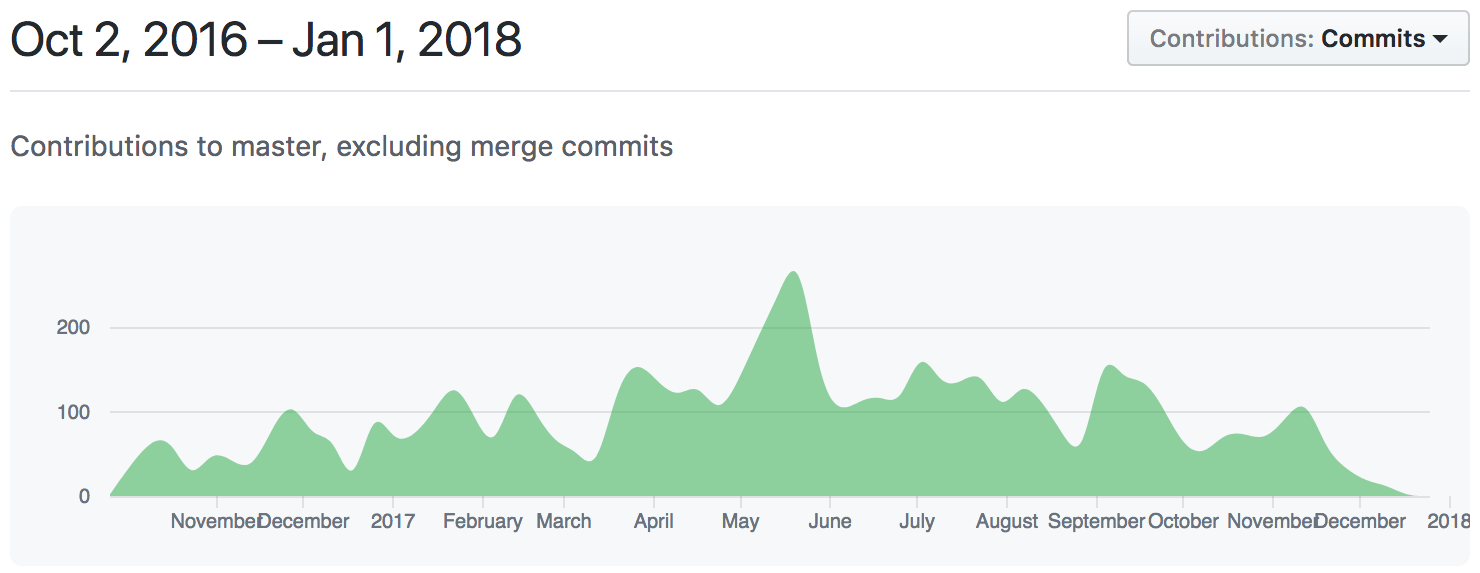
We worked with Fairfax for a little under 18 months, with our friends at XWP additionally joining us to work on additional features for a couple of months. Most of our time was spent on the edit screen and backend, building out the advanced features using our enterprise experience and open source tooling (including Cavalcade). Working together with Fairfax’s internal development team, we were able to build a functional, scalable CMS that their team continues to iterate on, and that will continue to be flexible and powerful well into the future.
Transforming WordPress for the modern newsroom
