-
AI Coding Agents: Claude Code Isn’t the Only Game in Town
A practical guide to the terminal coding agent landscape in early 2026. Just a year ago, most conversations about AI-powered development tools started and ended with Claude Code. Today, every major AI company has a coding agent, open source alternatives are flourishing, and new entrants seem to appear every week. That’s exciting for developers. It’s…
-

How to code with AI agents
What does it actually look like to work with AI every day as an engineer? In this piece, Human Made Senior Engineer Ivan Kristianto shares a practical, battle-tested workflow for building with AI agents. From spec-first thinking and parallel execution to disposable code and “vibe user” testing, this is a candid look at what works,…
-
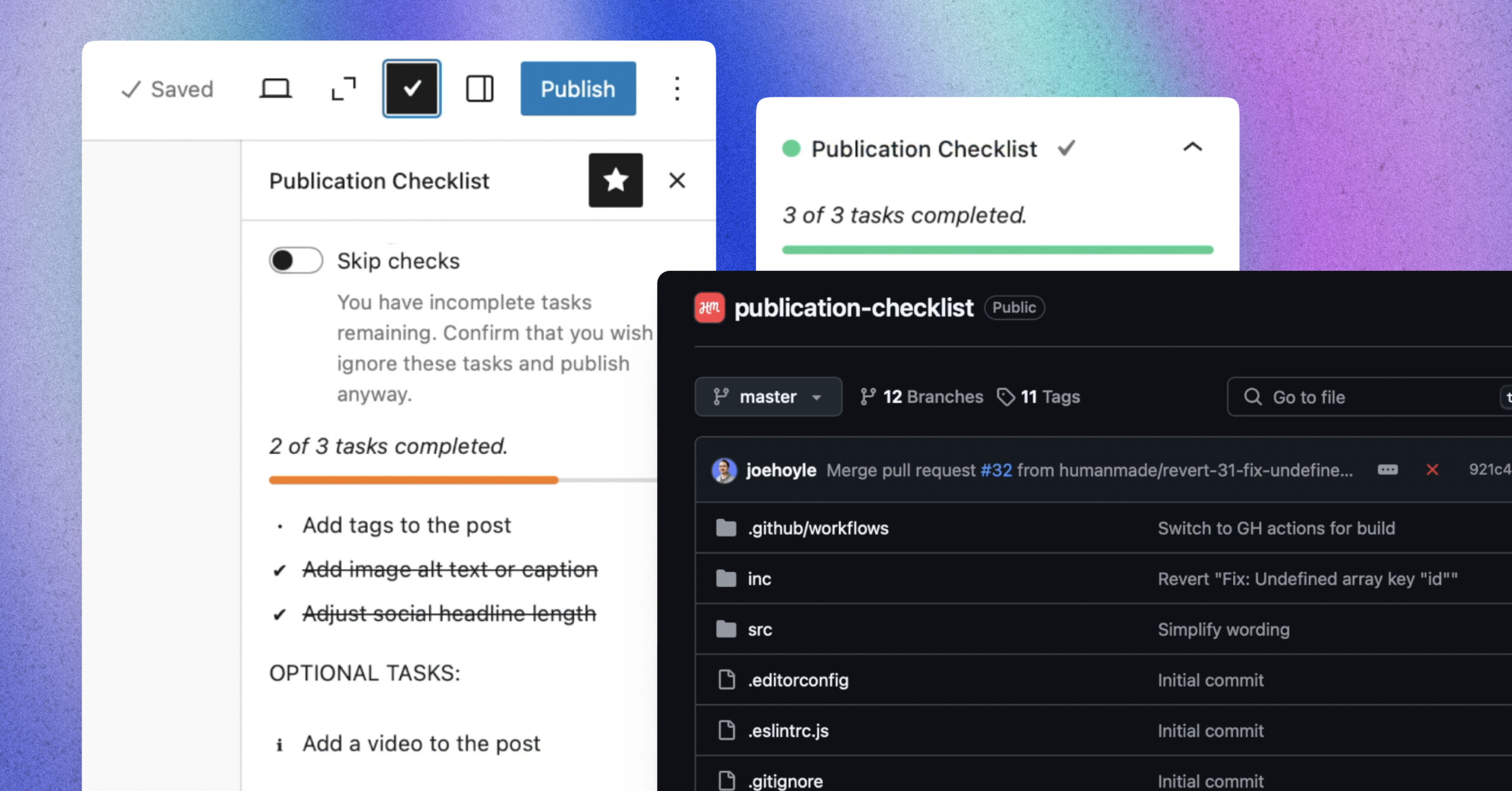
Publication Checklist plugin: quality control in WordPress
At Human Made, we’re committed to building tools to empower WordPress users, and to raising the bar for content quality and accessibility. That’s why we’re excited to share the Human Made Publication Checklist plugin—an open source tool designed to ensure your WordPress posts meet all the essential publishing standards before going live. What is the…
-
Introducing the WordPress Query Loop Filter
Filtering content within the Query Loop block is a common need for many WordPress users. Whether you’re showcasing recipes, travel blogs, or a mix of post types, having an easy way to sort and filter content makes for a better user experience. That’s why we’ve created the Query Loop Filter plugin – a simple yet…
-

Easy WP media management with the Asset Manager Framework
As content scales—especially at the enterprise level—handling a large volume of images, videos, and documents becomes increasingly complex and time-consuming. Human Made’s Asset Manager Framework (AMF) is a powerful open-source tool that tackles this challenge head-on, streamlining and simplifying media management for WordPress at scale. AMF in action One of the most exciting examples of…
-

Introducing Lottie Lite for WordPress animations
Animations are a valuable part of modern web design, adding visual interest and enhancing user experience. Lottie files, a popular tool for creating and displaying animations using SVG or canvas, are used by many enterprise companies for their flexibility and cross-platform compatibility. While Lottie Files offers a WordPress plugin, it comes with several limitations—bugs, performance…
-

Enhancing Japanese search relevancy with Elasticsearch
Improving the search relevancy for Japanese (including Chinese and Korean, known as CJK) poses unique challenges, but Senior Web Engineer Ivan Kristianto is on the case. Read on to find out what techniques he’s using to overcome difficulties with context, multiple scripts, and segmentation. The issue of search relevancy for Japanese language content can be…
-

Announcing Tachyon Version 3
With the release of Tachyon version 3, we’ve not only enhanced its capabilities but also streamlined its integration for enterprise WordPress users. Human Made CTO Joe Hoyle takes us through the key updates and how they can benefit your business. Tachyon is an innovative, on-demand image resizing and optimisation microservice, designed to enhance your digital…
-

Developers: here’s how to build your writing skills
It’s a common trope that writing is an under-loved aspect of a developer’s role, but it doesn’t have to be this way! With a little skill building and some top resources at your fingertips, you’ll be penning prose like a pro in no time. The topic of writing has come up frequently during one-to-ones within…
-

Opportunities to improve performance in Lighthouse 10
Version 10 of Lighthouse is here! Lighthouse is the automated, open-source tool used to improve webpage quality. Check out what’s in store with v10. Lighthouse 10 was recently released, and is already running on Pagespeed Insights. The most notable changes are that Cumulative Layout Shift (CLS) now accounts for a bigger factor (25% up from…
-

Grasping CSS fundamentals at WordCamp Valencia 2022
We’ve contributed to and attended dozens of WordCamps over the years, including the recent return of the grand WordCamp US. Whenever we can, we are delighted to share our work, ideas, and expertise on WordPress development, remote work, project management, and more to WordCamp audiences, no matter the geography or language. Recently, Human Made Web…
-
1001 ways to implement Gutenberg blocks
The major update in 2018’s WordPress 5.0 release was the Gutenberg editor. Facilitating more visual content creation, Gutenberg blocks have a multitude of uses, and there are many specific ways and situations to create Gutenberg blocks. While the flexibility and freedom of the blocks system is great, sometimes too much choice can be overwhelming. To…

